Media Art "Polyhedron, Mirror surface"
- Guest / Idea / UTAU Library / Music
- Tanaka
- Concept / UTAU Library / Music / Direction
- Sheeno Mirin
- Playback Control(TouchDesigner)
- Nagai
- System Architecture
- naporitan
- System Infrastructure Support
- yuu
- UI・Poster Design
- kohakuno
- Character Designs
- Asama
- M1 Transmission Lyric Video
- Cube
- M2 Transmission Lyric Video
- Yuzuri Hal
- M3 Transmission Lyric Video
- brutal_vap
This work was exhibited at the Osaka Kansai International Art Festival.
Concept and Design

Using “voice synthesizing software” to produce singing that repeats the same vocal data. Enjoying music via the Internet, which enables the same playback across the globe. These seem to contradict the notion of “art of the moment,” but is that really so?
The space where music is accompanied by users’ feedback and responses, and the myriad of derivative works that embellish the space. The diverse selections, interpretations, reductions, and transformations of the content that occur as many times as there are individuals. These processes are complexly interwoven, altering and enhancing the overall expression and quality. Can we not assert that there is a loosely interactive uniqueness to the musical experience of each instant?
In this work, we will reexamine the presence of each user’s “choice and imagination” concealed behind such “reproduction and replay,” and spatialize a sequence of processes. A novel synthetic voice persona will be generated, and a system will be devised to extract the image that the spectator has of the music performed by the synthetic voice, and incorporate it into the work itself.
Through this system, the spectator will witness a work that reflects the “thoughts” of the spectator preceding them. The imagination derived from this will also be extracted as a new “thought” and induce changes in the work. This cycle of “choice and imagination” gradually modifies the music and the performer, offering a “one-time experience” at each moment.
Tanaka's "Synthetic Voice Character "izationtanaka , kohakuno , Asama

For this work, the artist Tanaka was invited as a guest artist and worked with StudioGnu.
tanaka (たなか)
Musician and vocalist of the band Dios. Other members are Ichika Nito and Sasanomarii. He previously worked for Boku no Ririkku no Boyomi, which ended in 2019. He is also a producer and has been involved with a wide range of artists including Shingo Katori, KAF, Kuzuha, and Hypnosis Mike. Tanakaimo, a baked sweet potato shop that launches irregularly online and sold nearly 2 tons in just 2 months. Rather than simply making beautiful music, his theme is to express how we somehow survive in the world in various ways.
The core character was created by synthesizing Tanaka's voice with UTAU, a waveform-connected speech synthesizing software. The sound source is created with 7 moras of 3 continuous tone scales. Key settings were recorded in A3, C3, and F4, and a simplified original sound setting was used. Tanaka and Shiino Mirin sang three songs with different patterns, newly written for this project.

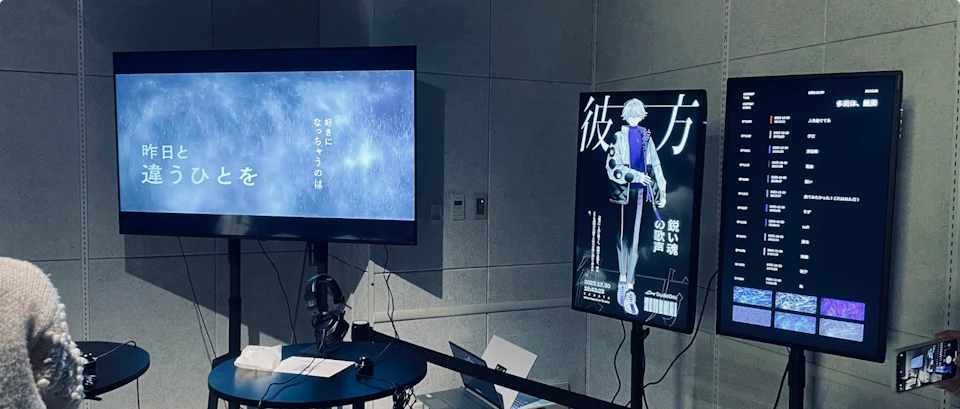
Then, a standing picture and catch copy are given to the finished synthetic voice, and it is packaged as a new synthetic voice character "Kanata (彼方)". The character design of kanata was done by Asama. The poster was designed by kohakuno. We attempted to implement the voice similar to the product while capturing the nuance and concept of the voice. In the work, the poster is constantly projected on a monitor.
Design and construction of a reaction collection and music video generation systemnaporitan, nagai, yuu
The music and posters completed above are incorporated into the system to implement interactivity. naporitan helped us design the entire system for this project. yuu provided support for the infrastructure and equipment for the system construction.
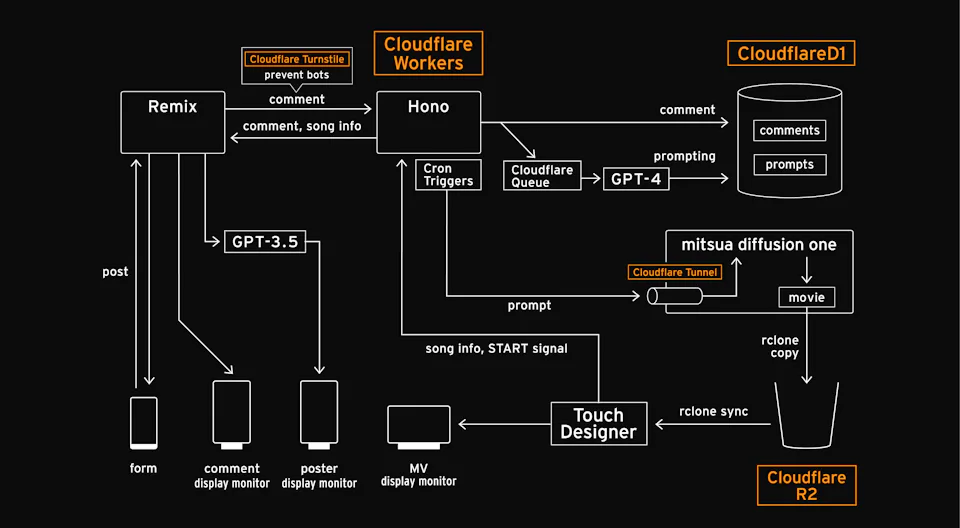
Fig. 1 shows a schematic diagram of the system. The music is synthesized with the music video by the playback system described below and broadcast from the music video monitor, and the viewer who watches the music video can input "thoughts" such as words or colors that come to mind when viewing the work via a form (Fig. 2) from a smart phone or tablet.
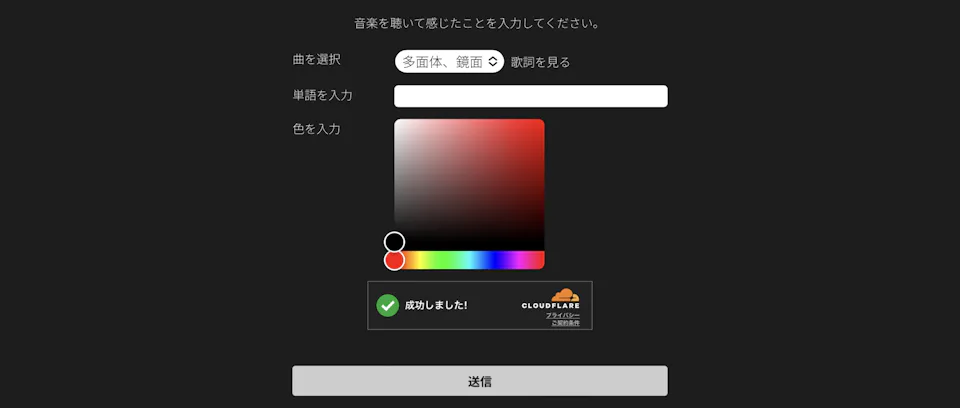
The viewer's input is collected by the server and passed internally to the "generation system. The system then generates, reconstructs, and overwrites the original catch copy and music video images with new text and images that reflect the "feelings" of the user. The generation system consists of two systems.
The first is a text generation system in which the built-in Chat-GPT API extracts elements from the collected information and overwrites the catchphrase on the poster displayed on the monitor every five minutes.
The second is the music video generation system, which incorporates the "Mitsua Diffusion One" generative AI model trained on images collected in a rights-cleared manner, such as public domain, CC0, and opt-in. The "thoughts" collected from the viewer are meticulously fed into the AI model and adjusted so that they are output as abstract patterns that do not rely on existing copyrighted works. NVIDEA A100 (80 GB) was used for output.
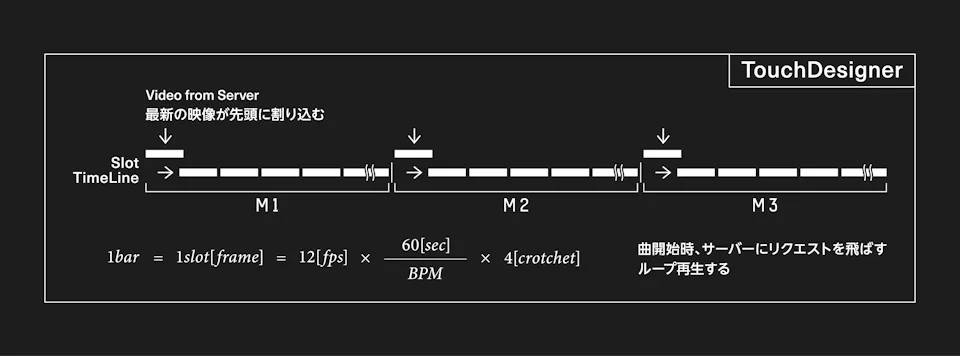
The output generated images are inserted into the music video in real time by the playback system (Fig. 3). The playback system was implemented by nagai.
Transparent Lyric Video for Generated MV SynthesisCube , Yuzuri Hal , brutal_vap

The playback system synthesizes a transparent lyric video from above onto the generated work, turning it into a music video. In this work, Cube cooperated in creating the transparent lyric video for the song "Polyhedron, Mirror Surface (M1)," Yuzuri Hal for the song "Daidanen (M2)," and brutal_vap for the song "Hayabusa (M3).